A Stroop Task Study Replication
Background(2): What is the Stroop Task?
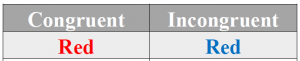
- Color words are presented in different colors and participants are asked to name the color of the word, ignoring the word itself
- Measures reaction time and accuracy as indicators of cognitive interference
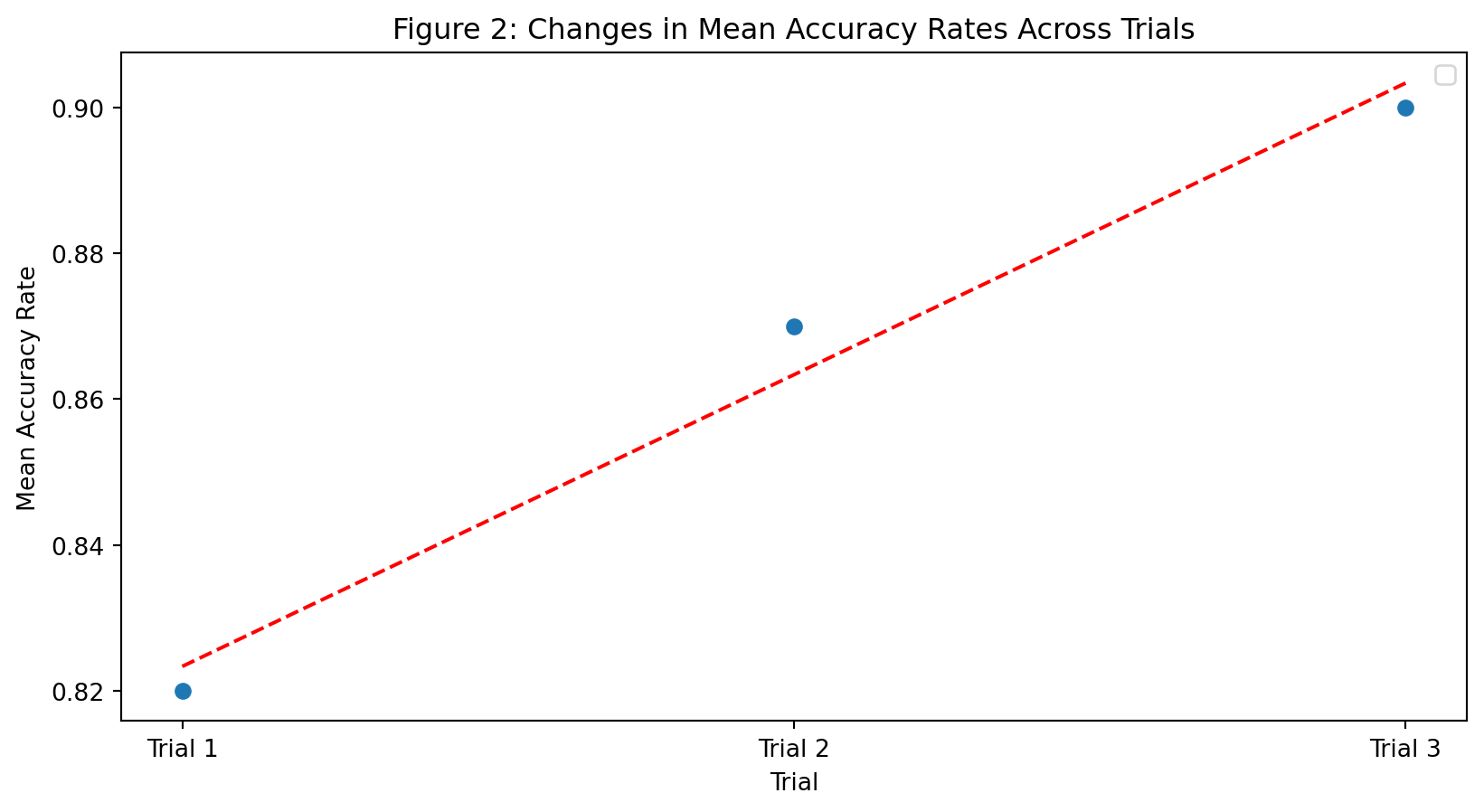
Descriptives - Reaction Time & Accuracy
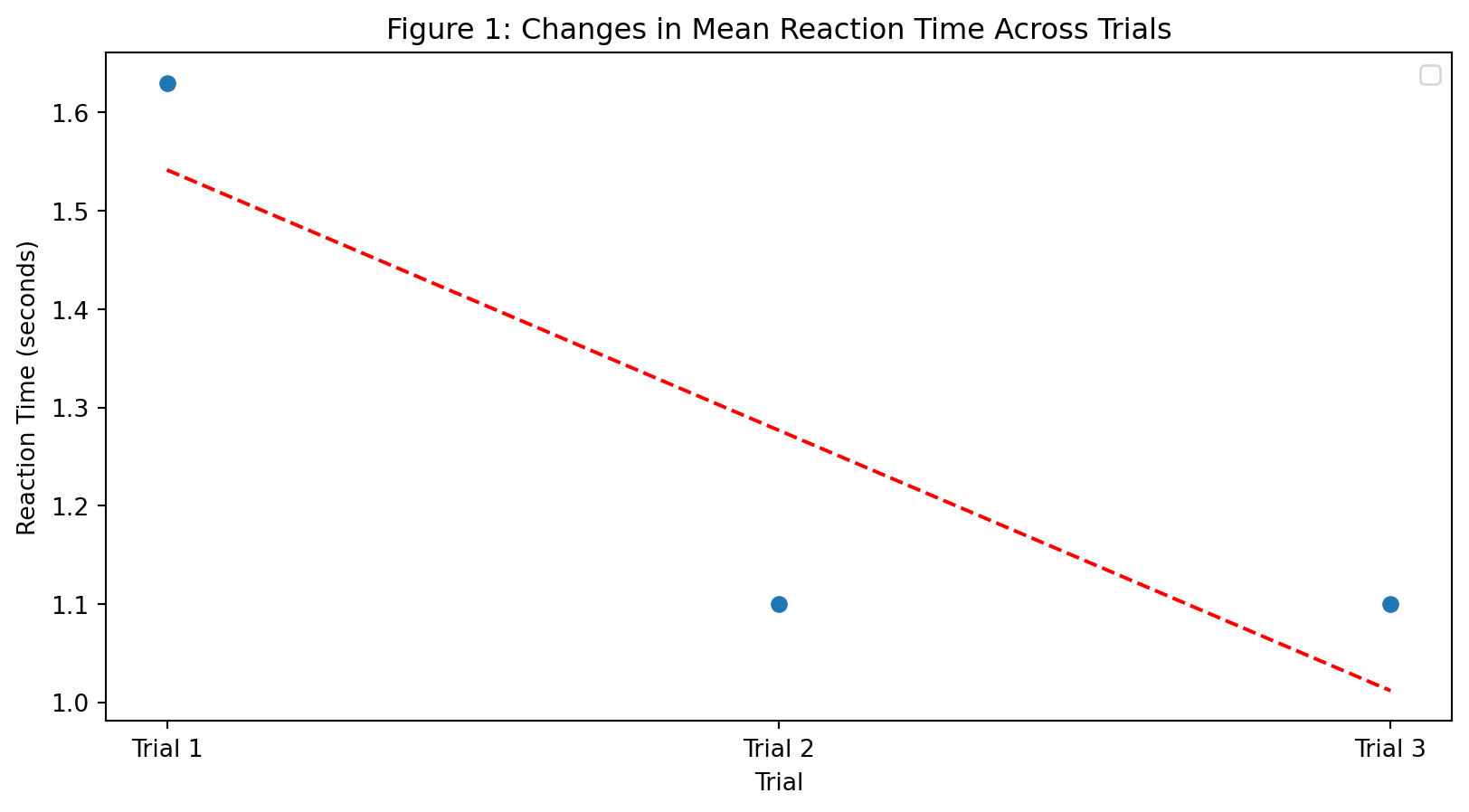
- Mean reaction time is 1.28 seconds.
- Mean accuracy rate is 86.4%.
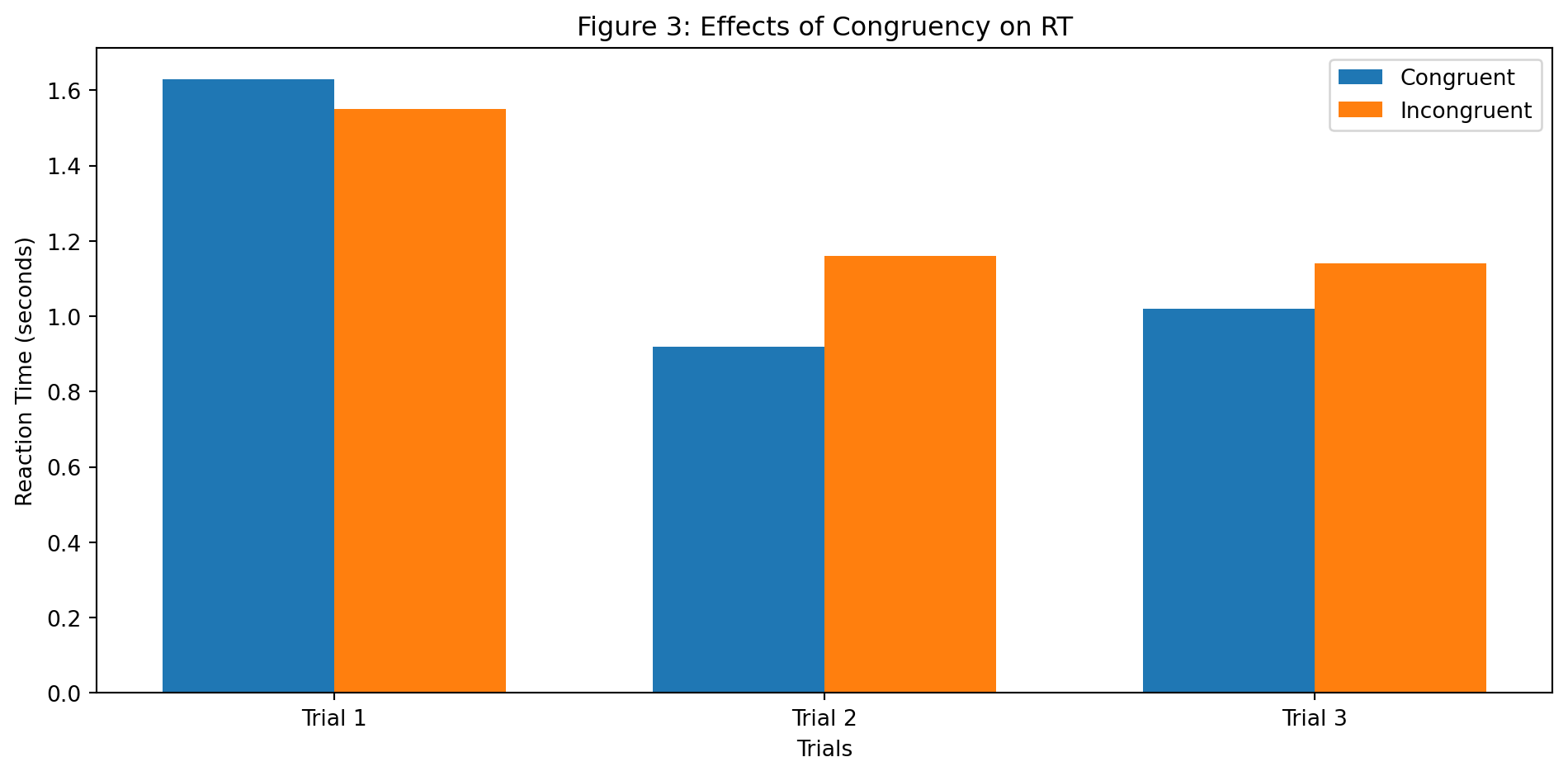
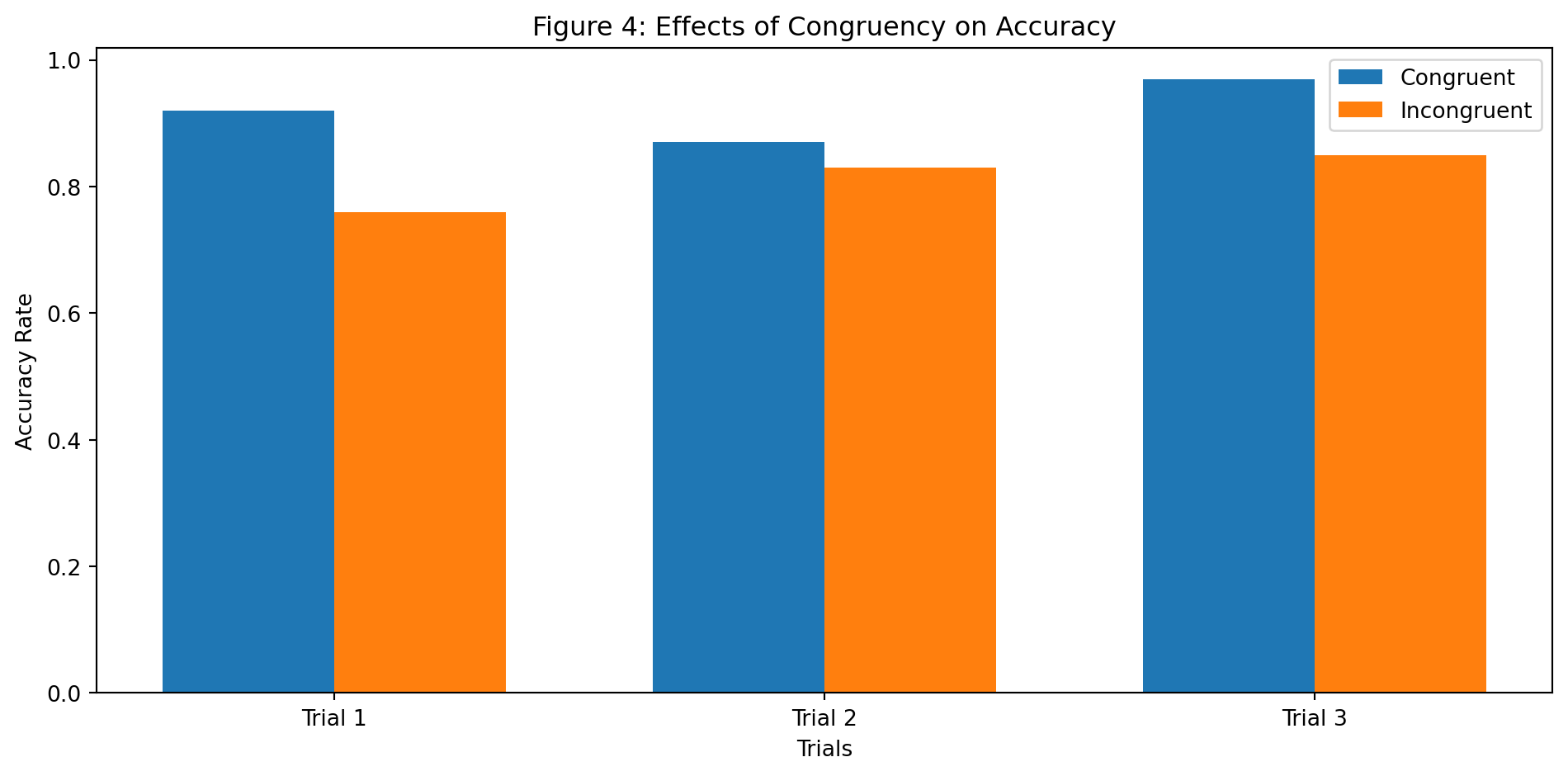
Descriptives - Effects of Congruency on RT & Accuracy
- Mean reaction time in incongruent trials is 1.28 seconds VS in congruent trials it’s 1.19 seconds
- Mean accuracy rate in incongruent trials is 81.3% VS in congruent trials it’s 92.0%
Analysis
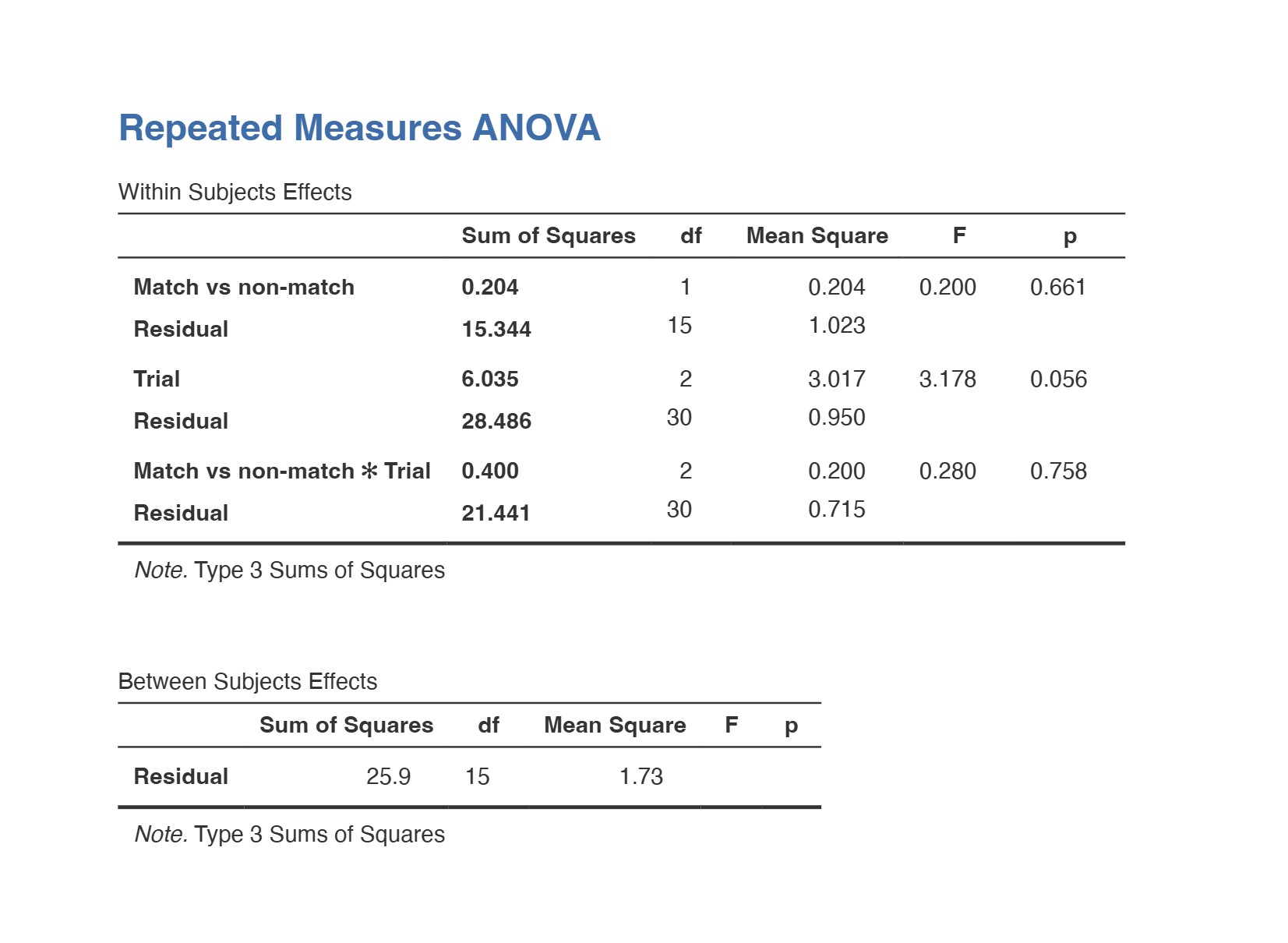
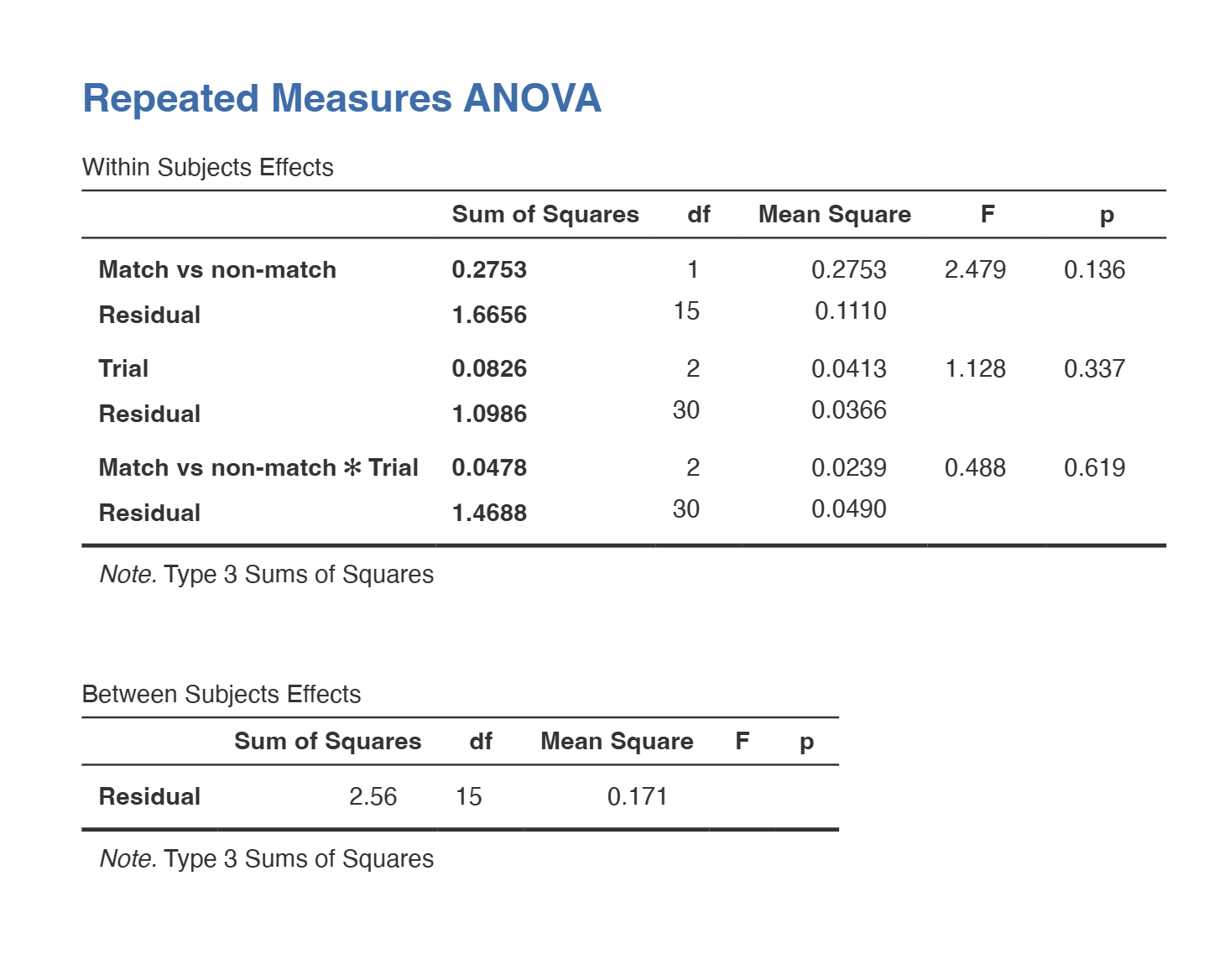
Two 2-Way Repeated Measures ANOVA tests were performed examining the main effects of trial and congruency on reaction time and accuracy, in addition to their interactions on both.
- Table 1
- Table 2